Published
- 9 min read
Tessera Lab 1 - The Database Layer

Objective
Design and implement the database schema for our events and ticketing using an SQL database (SQLite). This lab aims to introduce the concepts of database normalization and schema design, ensuring the database is optimized for efficient data retrieval and scalability. This setup is crucial for supporting the backend logic that will be developed in subsequent labs, providing a practical understanding of how databases interact with web applications and how they are integral to managing the application’s data lifecycle.
More Tools!
In our last lab, we installed some software and tools that are going to help us as we design and build our system. One of the tools we installed was sqlite3. Sqlite3 is a super lightweight database engine great for small projects and prototyping. It is estimated that sqlite runs on over 1 Trillion devices worldwide! Chances are, you have sqlite3 running in your pocket right now!
To work with sqlite, we could use the command line - however, data can get quite complex. Lets install a nice utility with an user interface so we can focus more on learning - and less on hand typing commands. We’ll be using DB Browser for our labs. Head over to their download page and get it installed on your machine now.
Lets open up DB Browser and connect open up our database. Sqlite3 stores its data in a singular file which makes it super easy to move data between systems. Last lab, we create a database file within our tessera folder structure (under the database folder). Click Open Database on the top of the screen and navigate to the file (should be called tessera.db). You should see something like the following:
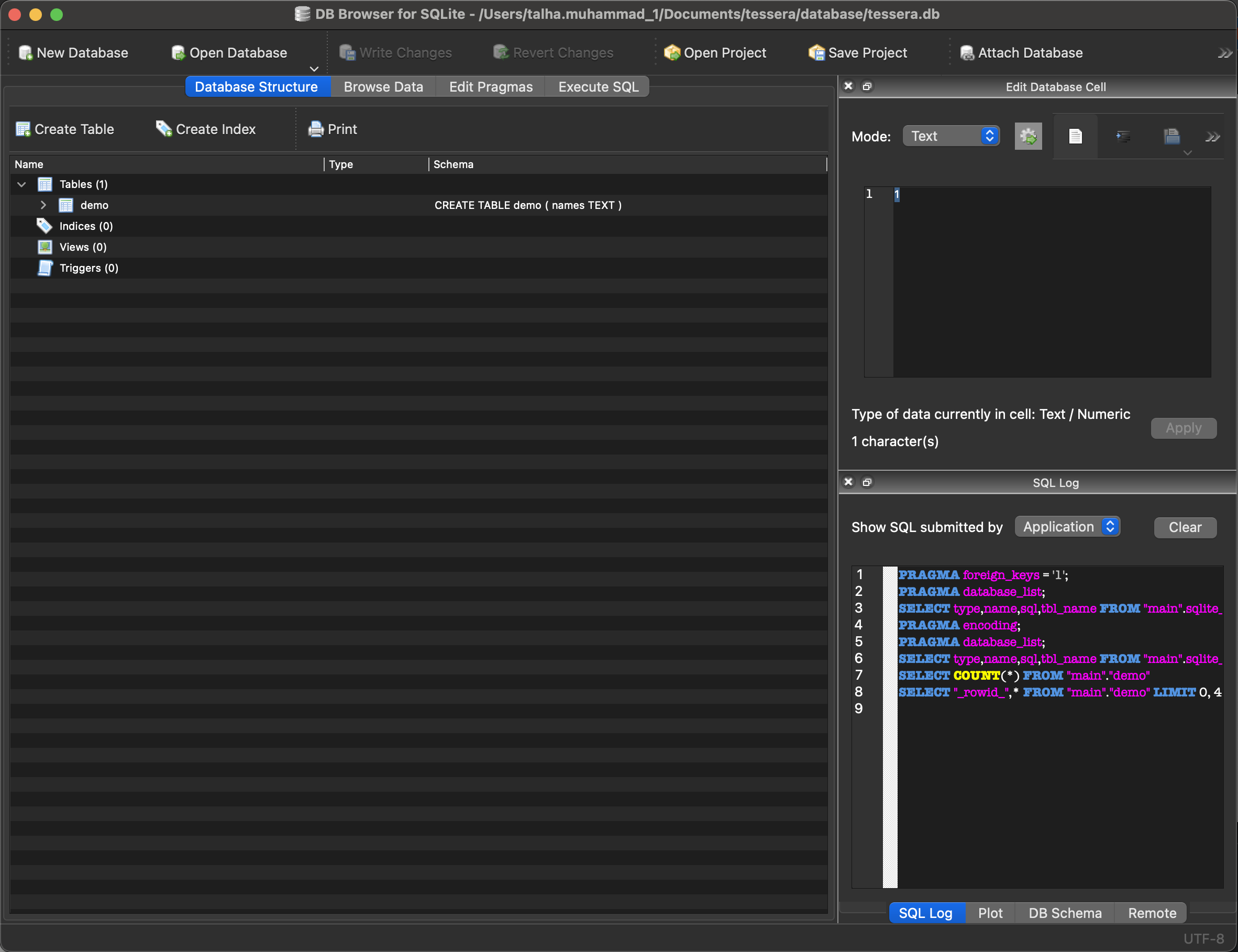
Lets click Browse Data and take a peak at whats there - you should notice some names! Recall that in the last lab we ran a script that populated the database with some names (magically). Today we’ll learn how!
Database Design
Alright - Lets get to it. Whether you love it or dread it, designing your database is crucial and can be a game changer for your project. Today, we’re setting the foundation for our Tessera ticketing system. We’ll walk through creating a clean, efficient database structure that not only stores our data but also makes sense of the chaos.
First up, we’ll tackle database normalization—don’t worry, it’s less scary than it sounds! It’s all about organizing our data efficiently to reduce redundancy and avoid pesky anomalies that could trip us up later.
We’ll identify our main players (or “entities,” to be fancy) like Events, Users, and Tickets. Each one has its own unique attributes and roles within our app. Then, we’ll map out how these entities interact with each other through relationships—because everyone needs a little connection, right?
By the end of this, you’ll have a solid database schema that’s not only functional but also scalable. Whether you’re a seasoned database enthusiast or a newcomer, I promise you’ll come out of this with a greater appreciation for the back-end magic that powers our applications. Let’s get started!
What is Database Normalization?
Database normalization is a systematic approach used to organize the data in a database efficiently. This process involves structuring a database in such a way that it reduces redundancy (i.e., unnecessary duplication of data) and improves data integrity. The goal is to isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships.
But why is this so important? Well, a few reasons…
- Reduces Redundancy: By minimizing duplicate data, you save on storage and ensure that data appears in only one place. This can significantly decrease the likelihood of inconsistencies.
- Improves Data Integrity: Normalization establishes relationships among tables and defines rules that add constraints to how data is entered or handled. This ensures accuracy and consistency of data across the database.
- Enhances Query Performance: Well-normalized databases can make queries more straightforward and more efficient. This is because they avoid complex joins and unions that can slow down the processing of queries.
- Easier to Modify: As the database structure is clearer and duplication is minimized, it becomes easier to make changes to the database without unintended consequences.
- Prevents Update Anomalies: Normalization helps avoid various anomalies during database operations, like update, insert, and delete anomalies. These anomalies can lead to loss of data integrity.
Normalization isn’t just about organizing data in a database; it’s about ensuring the database is reliable, efficient, and scalable. Whether you are building small applications or large systems, a well-normalized database is a backbone that supports the software’s performance and functionality.
Schema Definitions
Before we start tossing around tables and fields like confetti, let’s clear up what we mean by “schema”. In the world of databases, a schema is like the** blueprint of how your data is organized**. It defines the tables, the fields in each table, and the relationships between tables. Think of it as the architectural plan for storing your data, where every detail about the structure needs to be meticulously planned to ensure the building (or in our case, the database) stands strong and functions well.
Our Tessera Schema
For our Tessera project, we’re setting up a system to handle event ticketing, which means our database needs to manage users, tickets, and the events themselves. These are referred to as entities. Here’s how we’re going to lay it out:
Events Table: This is where we’ll keep the who, what, when, and where of each event.
| Field Name | Description |
|---|---|
| event_id | [Primary Key] Unique Identifier for each event |
| name | Name of the event |
| description | A short description of the event |
| date | The date of the event |
| time | The time of the event |
| location | The location of the event |
Users Table: Someones gotta buy those tickets!
| Field Name | Description |
|---|---|
| user_id | [Primary Key] Unique identifier for each user |
| username | User’s chosen username |
| password_hash | For security, we store the hash, not the actual password. |
| User’s email address |
Tickets Table: Keeps track of all the tickets purchased.
| Field Name | Description |
|---|---|
| ticket_id | [Primary Key] Unique identifier for each ticket (We could also consider this the barcode 🤔) |
| event_id | [Primary Key] Links the ticket to an event |
| user_id | [Primary Key] Identifies who bought the ticket |
| purchase_date | When the ticket was purchased |
| price | How much the user paid for it |
This Schema plan is great for our basic use case. It establishes relationships between our entities. A user can purchase multiple tickets which creates the classic many-to-one relationship between tickets and users (and tickets and events as well!). Sometimes, creating visual representations can help get the full picture. I recommend you grab a pen a draw out a Entity Relationship Diagram (ERD) for your schema. Dont shy away from adding more tables, fields, or trying something different!
Creating Schemas
Now that we’ve got our blueprint sorted out, it’s time to roll up our sleeves and start building our database tables. This step is like laying down the foundation of a house—get it right, and everything you build on top will be solid and sturdy. So let’s get those tables set up!
We’re going to be running SQL Commands from DB Browser. Near the top of your screen, you should see an Execute SQL tab. Click and youll see an input area where we can write some fancy SQL. See below for an example:
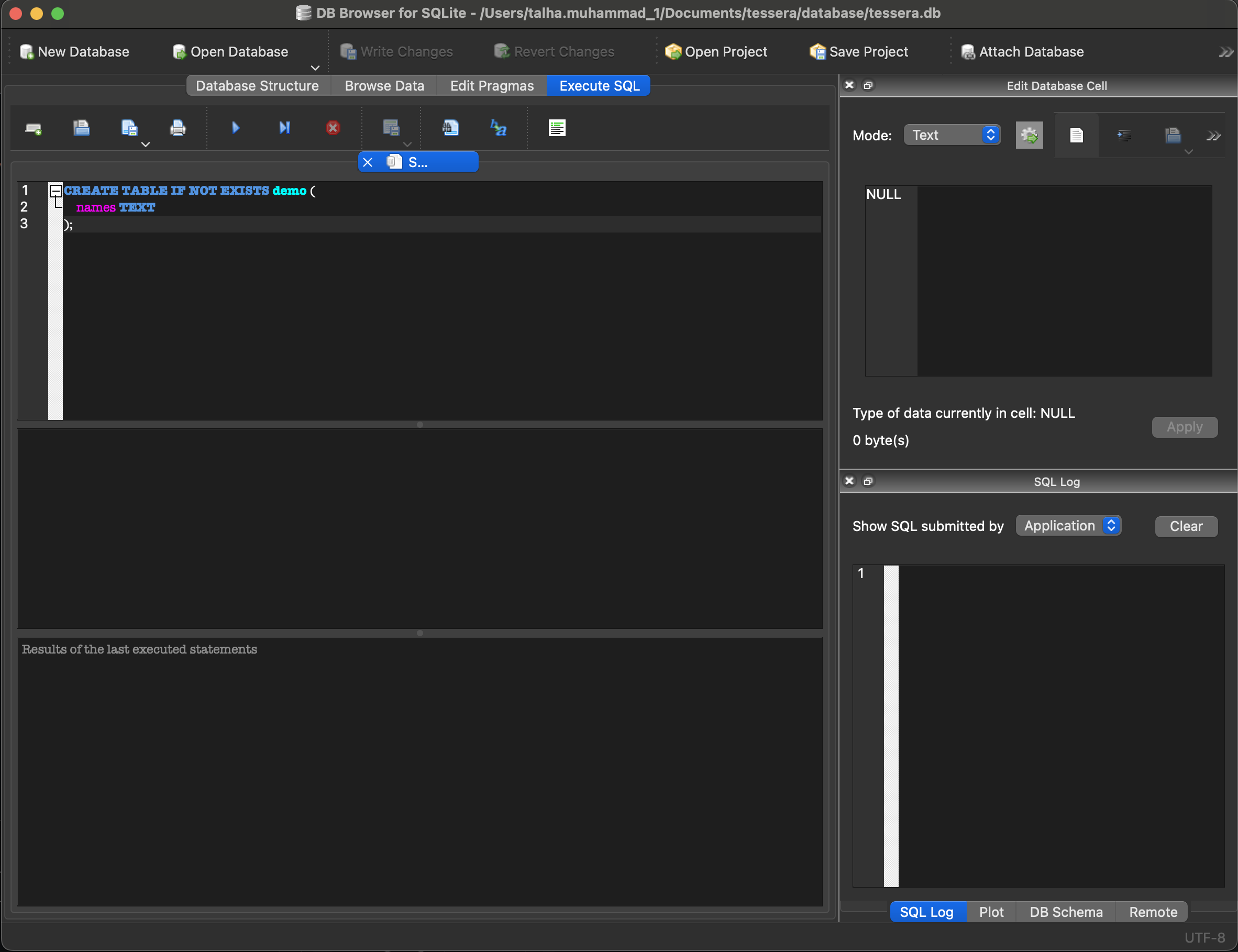
Lets Begin. Copy the following SQL Code into the input area and click the blue play button near the top of the window
CREATE TABLE IF NOT EXISTS Events (
event_id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
date DATE,
time TIME,
location TEXT
);
- Whats Going on here? We’re creating a new table called Events with some fields. Each field we’re defining some constraints such as the datatype (integer, string/text, date/time etc). Note that we also are defining the
event_idas a primary key which enforces every event to have a uniqueevent_id
CREATE TABLE IF NOT EXISTS Users (
user_id INTEGER PRIMARY KEY,
username TEXT NOT NULL UNIQUE,
password_hash TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
);
- Whats the gist? This table stores user info. Very similar to how we set up the
Eventstable. Note a new constraint where we are defining email and username as UNIQUE. Each user is required to have a unique username and email address
CREATE TABLE IF NOT EXISTS Tickets (
ticket_id INTEGER PRIMARY KEY,
event_id INTEGER,
user_id INTEGER,
purchase_date DATE,
price REAL,
FOREIGN KEY (event_id) REFERENCES Events(event_id),
FOREIGN KEY (user_id) REFERENCES Users(user_id)
);
- What are we looking at? The Tickets table links everything together. It references the
EventsandUserstables to track which user bought tickets for which event. TheFOREIGN KEYconstraints ensure that theevent_idanduser_idin Tickets must exist in the Events and Users tables, respectively.
Pro Tip: Test as You Go!
After creating each table, it’s a good idea to insert a few sample records to make sure everything works as expected. Try adding some test data and then run a few queries to see if you can retrieve it. Here’s a quick example to insert data into the Events table:
INSERT INTO Events (name, description, date, time, location) VALUES ('SQLite4 Announcement Party', 'Because 3 versions is not enough.', '2025-04-20', '10:00', 'SQL Arena');
And we can retrieve data like so:
SELECT * FROM Events;
Conclusion
We got the tools, and we created the foundation. We have a solid base for our project. But dont stop here! What other additions could we do to make to allow for more features in the future? Could we improve our schema designs? What are some limitation you can think of?
For Homework, try writing queries that acomplish the below use-cases
- Write a Query that returns all the tickets for a specifc user
- Write a Query that returns events between certain dates
- Write a Query that returns users who have spent more than $100.00 on tickets
- Get a leaderboard! In your test data, who has the most tickets?
- Advanced: Write a single query that pulls every unique username in the database, and lists an aggregated value representing the total amount of money the user has spent on tickets
In the next Lab, we’ll learn about how we can build APIs to read and write to our new database!